Abstract
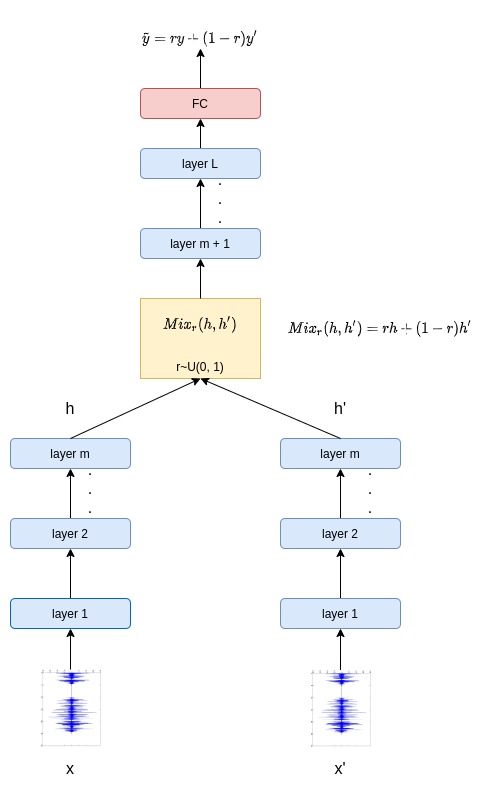
This paper presents SpeechMix, a regularization and data augmentation technique for deep sound recognition. Our strategy is to create virtual training samples by interpolating speech samples in hidden space. SpeechMix has the potential to generate an infinite number of new augmented speech samples since the combination of speech samples is continuous. Thus, it allows downstream models to avoid overfitting drastically. Unlike other mixing strategies that only work on the input space, we apply our method on the intermediate layers to capture a broader representation of the feature space. Through an extensive quantitative evaluation, we demonstrate the effectiveness of SpeechMix in comparison to standard learning regimes and previously applied mixing strategies. Furthermore, we highlight how different hidden layers contribute to the improvements in classification using an ablation study.
#
#
#Supplementary notes can be added here, including code, math, and images.
Narayanan Elavathur Ranganatha
Research Assistant, Vision & Learning
My research interests include computer vision, robotics